(1)16进制:
他就是一个数字的呈现形式,这个真的不能再解释了。数字10,16进制表示就是A,二进制表示就是1010。
(2)ASCII码:
1960年代美国制定的字符编码,将英文字符与二进制对应起来。举例来说16进制30代表数字0、61代表英文字母A。(3)Unicode:
英文字符不能打遍全球啊,全球有那么多文字,而计算机却只认识数字。以“我”这个字为例,如果没有一个统一的表示方式,你用AA表示(仅举例),他用BB表示“我”,那计算机岂不是要疯了。于是unicode出现了,它是个非常大的集合,把世界上所有的文字都定义了唯一的数字表示方式。注意它定义的是“文字”与“数字”的对应关系,就是把“我”这个字给个唯一标志的数字“AAAA“(仅为举例)。(4)Unicode的问题:
unicode既然表示了全量的文字看起来非常好,但实际上它并不能普及。第一个问题就是它不能识别一串数字到底表示几个字符。举个例子,在unicode的码表中,二进制0100 1111 0110 0000如果表示一个字符的话,是汉字 “你”,但如果表示2个字符的话是英文字符O(0100 1111)和 `(0110 0000),这让计算机怎么搞?那有人说,为了解决第一个问题我可以把英文字符前面补0,让他也成为2字节,比方说我把O变成0000 0000 0100 1111。这样每个文字都是2字节表示长度就统一了,计算机每次读取2个字节然后判断不就行了?理想很丰满现实很骨感,这样做的话那存储空间、网络传输带宽都会膨胀,而且如果是4字节呢,是不是浪费更多的0来补位,所以unicode最终并未落实为编码方式,而是表示方式。(5)UTF:
随着互联网的普及,一种统一的UTF编码方式出现了,它真正的把unicode表示方式给转换成了实用的编码方式。那么它是怎么解决unicode的长度表示问题和资源浪费问题的呢?核心在于它变长表示法,他可以用1~4个字节表示一个文字,其编码规则只有两条:第一位是0,后面7位是unicode码。所以对于英文单字符来说,utf和ascii是一样的先把文字用unicode表示法记录成二进制,然后把这串二进制依次塞进如下格式的二进制串:第一个字节前面的N位全是1、第N+1位是0,剩下的8-N-1位补unicode的字串,后面的字节前两位全是10,剩下的6位补unicode的字串。对应关系如下:

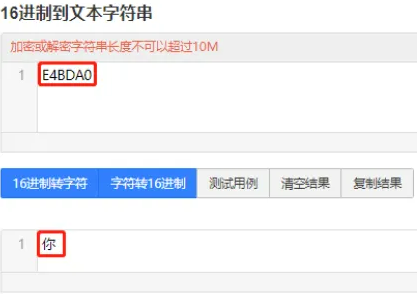
找个网站(例如https://www.wetools.com/unicode)查下"你"的unicode是4F60(0100 1111 0110 0000)。要用utf编码的话,它落在0800~FFFF之间,应该用3个字节表示。开始填充 1110 0100 1011 1101 1010 0000 。具体对应关系如下图所示:

最终形成的数字是1110 0100 1011 1101 1010 0000 16进制E4BDA0。找个网站把UTF转成中文(例如https://www.bejson.com/convert/ox2str/#google_vignette)